For over a decade, I have had a rack of servers which I have used for both personal and work related tasks. Indeed, here is a picture of my server rack from back in 2007 (with 6U of rack space containing what was at the time around $140K worth of high-end network switches).

The rack has changed a fair amount since then. I presently do not have the massive CPCI (CompactPCI) chassis mounted… I don’t know if I want to try to get a new backplane for it, along with trying to fill it out with newer 64-bit Intel as well as PPC cards and such as some point, or just continue with more systems like the Dell 2950 III or newer, which has replaced a number of those other systems (most of which were running Athlon 2500 and similar processors). But where I have 17 hosts (counting anything with an IP address as a host) visible in that picture, on 4 different subnets/VLANs, I currently have about twice that many hosts on twice that many subnets. The big difference is, I have half that many physical boxes, and the rest are either virtual machines or containers… many of which reside on that previously mentioned Dell 2958. The reason is, if I want to try a slightly different configuration, such as to do Node.js programming instead of PHP or Python, or if I want to isolate one application server from another, a few keystrokes, and I am soon running another machine, almost like I went out to the local computer store or WalMart and bought a new machine. All thanks to the fact that I can allocate processors, memory and disk to a new virtual machine or container. Indeed, this is how companies do things these days, whether they do it in their own datacenter, at some CoLo site, or by purchasing virtual servers or generalized compute resources from someplace such as LiNode, Rackspace or AWS. And depending on what I do (e.g. do I use a container instead of a full blown VM), I can spin them up just as fast.
The downside
Now, this can be a bit of a pain to manage at times. If I want to run a container with its own IP addresses, or to spin up a full blown VM, I have to allocate IP addresses for the machine. In addition, for the latter, I have to define things a bit further and say that I want a given base OS on it, with these packages out of the thousands which the OS could have installed, with a given network configuration, disk layout, and in the case of a virtual machine, with so many CPU cores, so much RAM, and so much space for a virtual disk image. And above all else, I don’t want to have to go through the hassle of entering a bunch of stuff to install a machine just like I did one six hours, or six months ago… just a couple of commands, and come back a bit later and having things just the way I wanted them. This is something I wanted well before I was ultimately responsible for the UN*X servers at CompuServe, or the UNIX install for the hundreds of AUDIX and Conversant machines manufactured every week when I was working at the Greater Bell Labs… and it follows a philosophy I picked up even before I started college, and had just started using computers…which is…
Do it once by hand… OK. Do it twice by hand… start looking at how to get the computer to do it for you. Do it more than a few times more… stop wasting time, making mistakes and being stupid… MAKE THE COMPUTER DO IT!
For my VM and physical machine installs, this means I use RHEL’s Anaconda and its Kickstart functionality, along with Cobbler. Where Michaelangelo goes “God, I love being a turtle!” in TMNT… for me, it is “G*d, I love being a UNIX/Linux Guru!”. With these, with these commands, I am installing a new machine, and have its virtual console up so that I can watch the progress…
koan --system=newvm --virt
virt-manager --connect=qemu:///system --show-domain-console newvm &
But guess what… I can even make it more robust, handle things like validating names, dealing with “serial” consoles, and more with a BASH shell script, and reduce it down to just this:
koan-console newvm
But… there is still room for improvement. This is because:
- Whether through the command line interface, or through the web user interface, Cobbler does not do so well on managing IP addresses. It really was not intended to do so, even though it can write my DNS files for me.
- Cobbler is not setup to maintain more than the minimal information about a system to get it installed and up on the network. While it has a field for comments, it does not really track things like where the machine is, what hard drives are in it, etc.
- While you can use post-install scripts to talk to Cobbler and trigger other things like an ansible playbook being run to create things in nagios or other programs, or to install additional software, it is not the greatest.
And so… not being a fan of swivel chair operations any more than I am of doing the same multi-step process repeatedly… there shall be a better way. Now while this could be something like Puppet, Chef or something else, I have looked at those, and none of them quite fit the bill… and so, I have decide to start a project to accomplish a few small things to begin with, and go from there. It needs to have the following functionality (for starters):
- It needs to be able to talk into Cobbler for install related stuff, but at the same time start using something like phpipam for the IP address management. If I am saying I want a new VM for say a development exercise as a part of an interview for a potential employer, it has certain subnets I want it to be on, etc. If we are talking a web server which I want to host a new WordPress site, it goes on another.
- If I want it to have access to a MySQL or PostgreSQL server, I want the rules to be created in my firewall automatically.
- At the same time, based on the type of server, I may want to have it added to the hosts being monitored by nagios, or specially filtered in my logs, etc. And, it may be that I want it to be included in Ansible as well.
- To go along with all this, I want an end-point to which I can direct the barcode scanner on my phone, scan something like a disk serial number, and pull up the information about that disk, such as when I purchased it, what machine it was last used in, etc.
- Should I wish more information, I also want to be able to have links which will open up a new tab talking to my filer, firewall, Cobbler or whatever (see this post for what this is replacing, in part from a programming perspective).
Given how this program will be all seeing into my DevOps systems, and how it will be a bridge between them… what better name than Heimdallr, the guardian of Bifröst, the rainbow bridge.
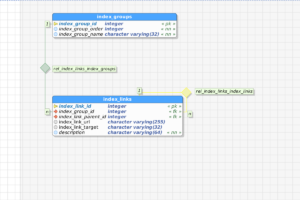
It’s still in the process of condensing in my mind, and I am still writing up the user stories and tasks on top of the initial set of requirements, but things like REST are our friends, and I may very likely even introduce the ability to add short-lived guest accounts, defaulting to read-only, as a means of showing off. And, I do have some other commitments, but I hope that at least the core of this will come together, using REST, MVC (I have debated a little about writing this in Zend Framework 3 and PHP 7, but I do so much PHP, and many of the other applications out there in this arena such as Cobbler and Ansible are using Python and Django, so…). But my thoughts are that this will be a very Agile project, starting off with the core idea and going from there… beginning with talking with the database, where so much will have to be located, if it is not already, such as my disk database.