So, as a part of my working to retire an ancient (20 year old) server which I have been using as a NFS server, among other things, I had one major task before me… fix things so that my NAS server could be used for the what I intended. But I was having some issues around 8 years ago when I first tried this, and I don’t remember all the issues, since work kept me from attacking this problem at the time. With my NAS software, TrueNAS Core (back then, it was still called FreeNAS) being essentially EOL in favor of a new version with a different name, I decided to attack the upgrade to TrueNAS SCALE this week. I say “this week”, because I wanted to be sure to backup all the data I had only on my NAS server, and nowhere else. And when you are backing up multiple terabytes of data, even with gigabit ethernet, that takes quite a while. And, had it failed, I was just going to skip using the fancy NAS software with its ZFS filesystem, and go for a regular Linux install to make a NFS server initially, then add other services as I went along.
My first task was to try to reproduce some of the issues I was having. One of the biggest issues was that while my ancient NFS server worked without issues, it turns out that when trying to use my NAS server, I was being prompted for password, since my SSH keys were not being used. This is a huge issue for me, because I am always connecting between all my hosts (over 20 of them), and it goes from being just a nuisance to a major PITA. Back then, I suspect that I had just written it off as a SELinux issue, since around that time, I was really going in on the idea of having it in enforcing mode, rather than permissive mode. So, while reproducing it, I did a bit of digging (with far better knowledge of SELinux, sssd and idmapd), and found that back when I first had this problem, my user and group IDs were not being mapped correctly. But today, I got the critical clues with debugging turned on. The two key lines were:
Oct 19 10:36:29 devhost kernel: NFS: v4 server nas.xyzzy.ka8zrt.com does not accept raw uid/gids. Reenabling the idmapper.
Oct 19 10:36:24 devhost nfsidmap[1840]: nss_name_to_gid: name 'cinnion@xyzzy.ka8zrt.com' does not map into domain 'ka8zrt.com'
This combination gave me the critical clue… idmapd might need tweaked. Sure enough, changing the domain name in /etc/idmapd.conf fixed that issue, and I am preparing to push that change out to all my other hosts. More on that in a bit.
So, to do the upgrade, I just selected the dropdown on the TrueNAS Core to select the latest stable TrueNAS SCALE release as documented in the migration guide as the update train. I then told it to download and apply the update, and about 30 minutes later… voilà (I love autocorrect for helping me add that accented character!). And here, I noticed the first of the minor gotchas… when trying to get at my home directory, I was getting an “Unknown error 521“. It turns out that the host I was using to do my testing had stale NFS information. Easy enough, just reboot to clear that mount to start fresh, and sure enough, it worked. (Sorry. No, I did not try just restarting the automounter or such, it is just a development server I use.)
Now, a second glitch I have run into is with ansible. I use a redis cache for storing facts about all my hosts, and it was confused and trying to use the path to python which was on the FreeBSD install of TrueNAS Core, not the one for the debian based TrueNAS SCALE. Easy fix…
[root@resune ansible]# redis-cli
127.0.0.1:6379> del ansible_factsnas
And after that, my gather-facts playbook (full playbook can be seen here) got a second error. While it detects the server as a libvirt host, libvirt is apparently not running. Another easy fix… I just change
Notice the additional lines at the end of each task? Easy enough, and if/when I decide to actually host a virtual host there, I just remove those lines. But I am not likely to do that, as this is not as beefy a server as the one on which I run my virtual machines, such as my web server, which is dedicated to that task and currently has 4x the RAM and faster CPUs. And it certainly is the case given that the ZFS cache is taking around 75% of the RAM in this machine!
Now, to cleanup tasks, such as to copy my home directories from the old machine. Sure to take some time…
A brief update on the ongoing process of getting a new, up-to-date cobbler server running with the associated DNS and DHCP services. We discuss some of the issues encountered so far, including briefly discussing SELinux issues, and touch upon next steps which will hopefully have us successfully complete the installation.
You can view the video, which is the first of a multi-part series, on my YouTube channel, or go directly to thevideo.
It has been awhile since I have posted anything here, mainly due to work, and more recently the lack of it. One of the things I have been doing while pursuing a new job is upgrading one of my core servers, where my DNS, DHCP and cobbler servers run. It is an older, home-built 4U server with an Athlon 2500 processor, and has functioned remarkably well for more than 15 years (as they say, if it ain’t broke, don’t fix it). But in recent months, it has started suffering from some disk issues, and in the interests of up-to-date software, lower power bills and the like, I decided it was time to rebuild it as a virtual machine. And while starting the process, I figured I would do a video as I used Ansible to build the replacement VM from scratch.
You can view the video, which is the first of a multi-part series, on my YouTube channel, or go directly to the video.
Well, earlier today, I got a reminder that I had not upgraded PHP. Indeed, unlike most of my installs, the virtual host running my WordPress sites was installed from a Live CD, and was running the dated PHP 5.4 version which CentOS/RHEL 7 comes with as a part of their base. It is a joy of running an operating system which comes with “long term support”, aka LTS. When an OS such as CentOS/RHEL, or Ubuntu’s LTS releases is going through the release process, the out-of-the-box repositories result in configurations are pretty much set in stone as to what versions of given software packages are included, and they don’t always take into account things like how much longer software package X will be supported. So when the process started for RHEL 7.0 (from which CentOS 7 is compiled) in late 2013 for the July 2014 release, they packaged things like PHP 5.4.16, Python 2.7.5 and other old packages into the release, and at a point in the release cycle, even if there is a minor version upgrade (from say 5.4.15 to 5.4.16), they do not pick up the new version, because of all the testing which would need to be done to guarantee stability. They might backport certain security fixes, but no more until the next release. And then, through the entire 7.x lifecycle (or the lifecycle of say Ubuntu 10.04LTX), it is pretty much a given that PHP would remain a 5.4.x release. And for RHEL, this cutoff date was actually such that PHP 5.5, which was released June 2013, much less PHP 5.6, which was released August 2014 have never made it into the core CentOS/RHEL repositories, and are installed by default when you install the package called “php”. The result is that RHEL (and thus CentOS) were running with versions which were no-longer supported… indeed, 5.6 patches were no longer being released to be backported either, since support for 5.6 ended this past December. And for Python, it is much the same story, with releases through 2.7.16 now being available.
Why are LTS releases out there? Because sometimes, even the changes going from say 2.7.5 to 2.7.6 can cause issues for software vendors trying to support their software, and when you start talking about going from say a 2.6.x to 2.7.x release, or worse, a 2.y.x to a 3.y.x release, the odds of that happening increase, sometimes significantly. Indeed, changes like that often result in the downline vendors having to go through their own release cycles, which can be quite expensive. And ultimately, you have a battle with multiple sides trying to come to an accord which balances things like finances, security, new features and more, and where the costs and risks can easily run $100K up to values in the millions, depending on application, the number of installs, etc. (When I was at Bell Labs Messaging, a simple patch to the OS for a OS bug might start with $5K or more of testing by myself, before it even hit our QA team, where bundled with other software patches, a testing cycle might run another $100K easily, all for a new release of Audix or Conversant… and until then, it was only installed manually on very select customers who had run into the problem and could not wait).
Now, depending on the operating system, there are options to help with this for those who are willing to expend some additional effort on the upgrades, and any testing of their environments. For PHP, this involves either installing from either the IUS Repository (“IUS” = “Inline with Upstream Stable), or Remi’s RPM Repository (run by the Remi Collet, who is a PHP contributor who also maintains many of the RPM packages for the Fedora/RHEL/CentOS distros). But these two repositories take slightly different approaches, and different versions of PHP could not traditionally be installed side-by-side.
For myself… I actually used the IUS repository… I dislike how the Remi versions of the RPMs install everything under /opt/remi/... instead of /usr/... And while it does not have PHP 7.3 yet, it does have PHP 7.2. And thankfully, the upgrade appears to have gone relatively smoothly. I tend to also prefer everything being installed via just via RPMs… why should I have to keep track of what was installed via RPM, as well as via PHP’s pear/pecl, or Python’s pip utilities. I am coming to use those utilities more, as so much is not available as RPMs… but it is a layer of nuisance I would rather not have to deal with. Unfortunately, the PHP ssh2 module required me to install it via pecl, which meant additional development packages needing to be installed right now. Sometime halfway soon, I hope to instead start looking at re-packaging some of these into RPMs myself. I would far rather have my own repo (I actually have two per distribution/release which I use, one for packages I figure to share, another for packages which contain things I consider to be security sensitive and will not). But for now, things seem to be good. 🙂
Will I ever stop using a LTS distro/release? No… I consider Fedora’s release cycle to have been enough of a pain in my ass, that outside of my workstation and perhaps a development VM, all of my servers will be of the LTS variety. After all, with changes which occured with Fedora 20’s installer, I had my workstation remaining at FC19 until just a few months ago, and here in a month or so, I will likely just say “reinstall my workstation” to cobbler, reboot the workstation, and get up the next morning to find it all shiny and new. And when RHEL 8 is released and CentOS 8 comes out, I likely will do the same with many of my servers, as I am currently doing some testing of the RHEL 8 beta release they made awhile back. Now, if only WinBlows were as easy…
While the title may indicate that this is a core dump post, I won’t quite say that it clears that hurdle… quite… But it is definitely a frustration which has raised its head a few times, and over the past 24 hours, went from a minor nuisance to a major frustration.
The problem, and the solution in theory
For those of you not familiar with Ansible, it is used for performing tasks controlled from a central host, and doing so using things called “roles” and “playbooks” (which you write once and reuse, like any good developer, DevOps member, etc.). And for your inventory, you can have variables associated with a given host, or for the groups to which it belongs. But, by default, Ansible overwrites the variables of the same name, based on a prioritized hierarchy. For example, let us suppose we have a variable listing users we want to add to a machine if they are not already there, which we will call provisioned_users. And depending on which group of machines, such as development servers, testing servers, or web servers (with say names of dev_servers, test_servers, and web_servers), there are a set of users which we want to be on the machine. But what if we have a machine which belongs to multiple groups, or there is a really special user, such as an application developer who helps the normal testers and DevOps folks at all stages in the life cycle. Normally, Ansible would then require you to go to all sorts of hassles for that. But I found a post by the folks at Leapfrog which talks about a plugin which solves this problem, and even shows some good examples to understand the problem better. And they even share their plugin for folks to use!
Now… for me, the problem came up with my letsencrypt-certs role, which I have been using to push my SSL certificates from a central administration host to the various web servers I have for both internal and external use (i.e. this one), along with the SSL certificates for my LDAP server, and more. This has meant that I have run into the collision on variables between groups and the host, and last night, I got a warning from my Nagios installation on a couple of those certificates needing “renewed”, which was mainly just my needing to push the certificates into place. And given that one of the certificates is a part of the collision… time to address the issue, and I might as well do it right. 🙂
The solution in reality
Well, in reality, I found a couple of gotchas… the first is that the instructions seems to imply that with a playbook in /etc/ansible/playbooks that the folder in installation step 4 would be /etc/ansible/action_plugins/… but this is not the case. Indeed, I got the following (with the verbosity cranked a bit):
# ansible-playbook -vvvvvvvvv update-certificates.yml
ansible-playbook 2.6.3
config file = /etc/ansible/ansible.cfg
configured module search path = [u'/root/.ansible/plugins/modules', u'/usr/share/ansible/plugins/modules']
ansible python module location = /usr/lib/python2.7/site-packages/ansible
executable location = /usr/bin/ansible-playbook
python version = 2.7.5 (default, Jul 13 2018, 13:06:57) [GCC 4.8.5 20150623 (Red Hat 4.8.5-28)]
Using /etc/ansible/ansible.cfg as config file
setting up inventory plugins
Parsed /etc/ansible/hosts inventory source with yaml plugin
ERROR! no action detected in task. This often indicates a misspelled module name, or incorrect module path.
The error appears to have been in '/home/cinnion/git/ansible-roles/letsencrypt-certs/tasks/main.yml': line 3, column 3, but may
be elsewhere in the file depending on the exact syntax problem.
The offending line appears to be:
# tasks file for letsencrypt-certs
- name: Merge certificates
^ here
And just putting it in the modules directory does not help. There, it complains that it does not start with the interpreter line (e.g. #!/usr/bin/env python or some equivalent). Instead, for a playbook in that location which uses it, the location would be one of these locations:
/etc/ansible/playbooks/action_plugins
/usr/share/ansible/plugins/action (the default, which is mentioned in the ansible.cfg file, and can be overridden there.)
or, in a directory named action_plugins directly under the role itself (e.g. parallel to the handlers, tasks, and similar subdirectories. Since I will be using this for multiple playbooks/roles (Keep things DRY!!!), and really dislike putting things in a directory like the default ansible uses (if it included /usr/local, I would have less hesitation, though spreading customizations out is still sub-optimal in my book), I created /etc/ansible/plugins/action, placed the file in that directory, and changed the config file to include that location.
A second issue comes up in that is a minor pain is that instead of being able to have a role which conditionally executes from the playbook based off the variable being defined, the task file in the role needs to do this condition handling. It is not a huge deal… it just means refactoring the file. But that is probably a good move in the long run anyways.
A third issue, which may just be caused by my using fact caching, is that even without specifying that the variables which are the result of the merge are to be cached, I am getting warnings about overwriting the fact. That will take some looking into at some point.
Now, to see how things work in real usage for a week or two.
For over a decade, I have had a rack of servers which I have used for both personal and work related tasks. Indeed, here is a picture of my server rack from back in 2007 (with 6U of rack space containing what was at the time around $140K worth of high-end network switches).
The rack has changed a fair amount since then. I presently do not have the massive CPCI (CompactPCI) chassis mounted… I don’t know if I want to try to get a new backplane for it, along with trying to fill it out with newer 64-bit Intel as well as PPC cards and such as some point, or just continue with more systems like the Dell 2950 III or newer, which has replaced a number of those other systems (most of which were running Athlon 2500 and similar processors). But where I have 17 hosts (counting anything with an IP address as a host) visible in that picture, on 4 different subnets/VLANs, I currently have about twice that many hosts on twice that many subnets. The big difference is, I have half that many physical boxes, and the rest are either virtual machines or containers… many of which reside on that previously mentioned Dell 2958. The reason is, if I want to try a slightly different configuration, such as to do Node.js programming instead of PHP or Python, or if I want to isolate one application server from another, a few keystrokes, and I am soon running another machine, almost like I went out to the local computer store or WalMart and bought a new machine. All thanks to the fact that I can allocate processors, memory and disk to a new virtual machine or container. Indeed, this is how companies do things these days, whether they do it in their own datacenter, at some CoLo site, or by purchasing virtual servers or generalized compute resources from someplace such as LiNode, Rackspace or AWS. And depending on what I do (e.g. do I use a container instead of a full blown VM), I can spin them up just as fast.
The downside
Now, this can be a bit of a pain to manage at times. If I want to run a container with its own IP addresses, or to spin up a full blown VM, I have to allocate IP addresses for the machine. In addition, for the latter, I have to define things a bit further and say that I want a given base OS on it, with these packages out of the thousands which the OS could have installed, with a given network configuration, disk layout, and in the case of a virtual machine, with so many CPU cores, so much RAM, and so much space for a virtual disk image. And above all else, I don’t want to have to go through the hassle of entering a bunch of stuff to install a machine just like I did one six hours, or six months ago… just a couple of commands, and come back a bit later and having things just the way I wanted them. This is something I wanted well before I was ultimately responsible for the UN*X servers at CompuServe, or the UNIX install for the hundreds of AUDIX and Conversant machines manufactured every week when I was working at the Greater Bell Labs… and it follows a philosophy I picked up even before I started college, and had just started using computers…which is…
Do it once by hand… OK. Do it twice by hand… start looking at how to get the computer to do it for you. Do it more than a few times more… stop wasting time, making mistakes and being stupid… MAKE THE COMPUTER DO IT!
For my VM and physical machine installs, this means I use RHEL’s Anaconda and its Kickstart functionality, along with Cobbler. Where Michaelangelo goes “God, I love being a turtle!” in TMNT… for me, it is “G*d, I love being a UNIX/Linux Guru!”. With these, with these commands, I am installing a new machine, and have its virtual console up so that I can watch the progress…
But guess what… I can even make it more robust, handle things like validating names, dealing with “serial” consoles, and more with a BASH shell script, and reduce it down to just this:
koan-console newvm
But… there is still room for improvement. This is because:
Whether through the command line interface, or through the web user interface, Cobbler does not do so well on managing IP addresses. It really was not intended to do so, even though it can write my DNS files for me.
Cobbler is not setup to maintain more than the minimal information about a system to get it installed and up on the network. While it has a field for comments, it does not really track things like where the machine is, what hard drives are in it, etc.
While you can use post-install scripts to talk to Cobbler and trigger other things like an ansible playbook being run to create things in nagios or other programs, or to install additional software, it is not the greatest.
And so… not being a fan of swivel chair operations any more than I am of doing the same multi-step process repeatedly… there shall be a better way. Now while this could be something like Puppet, Chef or something else, I have looked at those, and none of them quite fit the bill… and so, I have decide to start a project to accomplish a few small things to begin with, and go from there. It needs to have the following functionality (for starters):
It needs to be able to talk into Cobbler for install related stuff, but at the same time start using something like phpipam for the IP address management. If I am saying I want a new VM for say a development exercise as a part of an interview for a potential employer, it has certain subnets I want it to be on, etc. If we are talking a web server which I want to host a new WordPress site, it goes on another.
If I want it to have access to a MySQL or PostgreSQL server, I want the rules to be created in my firewall automatically.
At the same time, based on the type of server, I may want to have it added to the hosts being monitored by nagios, or specially filtered in my logs, etc. And, it may be that I want it to be included in Ansible as well.
To go along with all this, I want an end-point to which I can direct the barcode scanner on my phone, scan something like a disk serial number, and pull up the information about that disk, such as when I purchased it, what machine it was last used in, etc.
Should I wish more information, I also want to be able to have links which will open up a new tab talking to my filer, firewall, Cobbler or whatever (see this post for what this is replacing, in part from a programming perspective).
Given how this program will be all seeing into my DevOps systems, and how it will be a bridge between them… what better name than Heimdallr, the guardian of Bifröst, the rainbow bridge.
It’s still in the process of condensing in my mind, and I am still writing up the user stories and tasks on top of the initial set of requirements, but things like REST are our friends, and I may very likely even introduce the ability to add short-lived guest accounts, defaulting to read-only, as a means of showing off. And, I do have some other commitments, but I hope that at least the core of this will come together, using REST, MVC (I have debated a little about writing this in Zend Framework 3 and PHP 7, but I do so much PHP, and many of the other applications out there in this arena such as Cobbler and Ansible are using Python and Django, so…). But my thoughts are that this will be a very Agile project, starting off with the core idea and going from there… beginning with talking with the database, where so much will have to be located, if it is not already, such as my disk database.
Common Table Expressions, or CTEs as they are often called, are an area of SQL which can by some be considered to be no different than magic. This is because few of us use them, and even fewer of us use them regularly enough to make them like the familiar of some powerful wizard in some book. And just like those familiars sometimes do in the books, they can give us great frustration or even turn upon us like some demon or Djinn who has escaped the bounds we thought would control them. But all the same, they can be quite useful, and indeed, necessary for us to have a performant application.
An introduction by example
And I myself have used them in a number of instances, including:
Building up access control lists, where permissions can be inherited through roles.
Generating menu hierarchies.
Generating organizational charts.
Analyzing data to generate reports.
In many of these cases, will see records in a database which point at other records of the same type. For example, here is one where we have an employee record, where there is a reference to the supervisor (their manager, boss, or whatever term is used at that level of the organization).
Now, when generating the org chart, moving downward from someone in the organization, such as an executive, we could do this in one of two ways, which basically boils down to:
Have our program do the work.
Have our database do the work.
In general, you are actually better off doing the latter, since:
The database will tend to reside on a system with lots of resources (CPU, memory, disk), while your program may be running on a system with a much smaller set of resources, which can easily be replicated, etc.
Each query sent to the database uses those resources, as well as network bandwidth, with there being costs being setup to validate and prepare each query, to run it, to prepare the results, as well as in the transmission and consumption of those results. And this does not even consider that a new database connection may need to be created.
While we can certainly use things such as prepared statements in our program to reduce the overhead, and our queries may be simple, with a properly designed database, the database server can use its knowledge, as well as the expertise of its developers, to do things far better than we can.
Think about that employee database for a moment to see why. Suppose we are talking an employee database with 100,000 records (when I was at Lucent in what we termed the “Greater Bell Labs R&D”, we were over 150,000, so that is not an impossible figure), in which 90,000 of them are employees with nobody reporting to them, that could easily turn into 90,000 unnecessary queries sent to the server, or some similar nightmare, with all the associated execution time on both end, and all the requests going back and forth. So this is where a form of CTE called a recursive CTE helps us greatly.
Now, while referred to as a “recursive” CTE, it is really just a repeated iteration, where the records resulting from the prior pass are used to produce a new set of records, and it is repeated until no further records are returned to be placed into the temporary working table the server uses internally. Here is the CTE for the employees table.
WITH RECURSIVE report_tree ( employee_id, fname, lname, supervisor ) AS (
SELECT
employee_id,
fname,
lname,
supervisor
FROM employees
WHERE supervisor IS NULL
UNION ALL
SELECT
e.employee_id,
e.fname,
e.lname,
e.supervisor
FROM employees AS e
INNER JOIN report_tree AS emps ON (emps.employee_id = e.supervisor)
)
SELECT *
FROM report_tree;
When we look at this, we see the WITH block which defines the CTE as a prefix to the SELECT which uses it. That block consists of (in this case) an initial query (sometimes referred to as the “non-recursive” or “anchor” query), a UNION, and then the “recursive” portion, which references the containing CTE. In this case, we first get the batch of employees who have no supervisor, which may in fact be just a single record, or could be multiple records (such as the CEO, CTO, CFO, CLO, etc.). And in the next iteration, the bottom part will get those who report to the first set, with the following iteration getting those who report to the second set, and so on.
The one issue with the above CTE is that the output order, put bluntly, sucks like the vacuum of intergalactic space. There is no easy way of taking the output records and sorting them to even remotely resemble the organization. But there is a way in which we can address this, as we will see later.
My most recent encounter… (an in depth look)
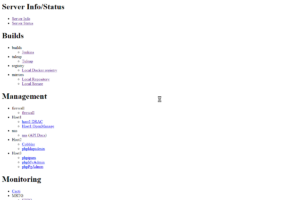
Now, the most recent item where I came across a structure which could use a CTE is this… I have a page which is displayed on some of my machines when I connect to them via my browser. For example, if I connect to my main administrative server, or to the machine which handles all my virtual machines, I get the following page (sanitized):
In looking to redesign this, and ultimately put it into a new application which I am writing (which I am currently calling Heimdallr), I wanted to put this into a database and turn it into a dynamic page. And when you look at this, it quickly becomes apparent that it should be represented as a hierarchy. It is, after all, yet another hierarchical menu, with all but the top nodes being HTML list items, and each leaf item having an associated URL, a target window (hidden to the viewer). Indeed, here it is in its source form:
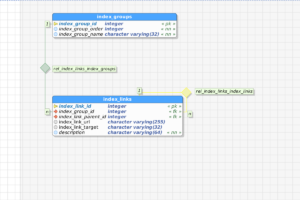
So, the first pass of this becomes the following database tables, shown in graphical format:
The index_groups table becomes something like this (intentionally shown as if “Management” was added after the fact):
ID
Order
Text
1
1
Server Info/Status
2
2
Builds
3
4
Monitoring
4
3
Management
While index_links contains records like the following:
Link ID
Group ID
Parent Link ID
URL
Target
Description
1
3
firewall
2
1
https://gateway.example.com
gateway
Firewall
3
3
Host1
4
3
https://host1-drac…
drac
host1 DRAC
5
3
https://host1:1311
host1-om
Host1 OpenManage
6
3
Host2
6
6
https://host2…
host2-cobbler
Cobbler
Now, as I said above, we could do this with loops making queries, but remember those 90,000 employees? While this menu only has 31 records half of them have no children, so we would be making roughly 16 queries with no results.
NOTE: Yes, we could group them and use queries containing code like WITH index_link_parent_id IN [ 1,2,3,4 ], but that quickly becomes complex, and could run into some limit. So again… why not let the SQL server do what it has been designed, and indeed is optimized to do.
So, how can we get those records out, and have them in an nice order, unlike the employee list? The first part is to have each record contain what is often referred to as an XPATH… a string which indicates how we arrived at the record in question. In this example, we are not going to use the /node1/node2/... syntax, but something similar… we will take the unique ID of each record in index_links, and add it onto a string, and each child will add theirs onto the end, using a ‘>’ character as a separator. It could be just about anything consistent, such as a colon, a dash, a period or a comma… just something which does not show up in our IDs, so we know where one ID ends and the next child’s begins. Were we to add an order to those records, we would just use it instead (or perhaps the order and ID, if we allowed for duplicate order values). And, as an added bonus, we will also use a trick to make the records of index_groups look like the records of index_links, so that we have rows for those records included in their spots in the hierarchy. And so, we have this CTE to get the data:
WITH RECURSIVE menutree (group_id, link_url, link_target, description, link_id, link_parent_id, xpath) AS (
SELECT -- Non-recursive
index_group_id,
CAST(NULL AS CHARACTER VARYING) AS link_url,
CAST(NULL AS CHARACTER VARYING) AS link_target,
CAST(index_group_name AS CHARACTER VARYING(64)),
CAST(NULL AS INTEGER) AS link_id,
CAST(NULL AS INTEGER) AS parent_id,
CONCAT('', index_group_order)
FROM index_groups
UNION
SELECT -- Recursive
CAST(NULL AS INTEGER),
l.index_link_url,
l.index_link_target,
CAST(l.description AS CHARACTER VARYING),
l.index_link_id,
l.index_link_parent_id,
CONCAT(mtree.xpath, '>', l.index_link_id)
FROM index_links l
INNER JOIN menutree mtree ON (
(l.index_link_parent_id IS NULL AND l.index_group_id = mtree.group_id)
OR
(l.index_link_parent_id IS NOT NULL AND l.index_link_parent_id = mtree.link_id)
)
)
SELECT * FROM menutree
ORDER BY xpath;
The non-recursive part starts by getting the records out of index_groups, and adding in columns with NULL values to make those look like the other records, and then in the “recursive” block, we have our query to add on the next set of records. The things to note here are:
We are using column names on the CTE itself to save ourselves some typing.
For our INNER JOIN… ON, we have two conditions or’ed together.
A condition to join our group and link records for the first round of joining, and
A condition to join child links to their parent links.
We are having to use CAST() to have our column types match up, which is one reason why a CTE such as this can be particularly tricky.
The order is not exactly identical. In particular, the fact that the MRTG record was added last and the SW02 record placed under it, as if by an afterthought, means that the MRTG entry and its children will come last, rather than following the entry for Cacti.
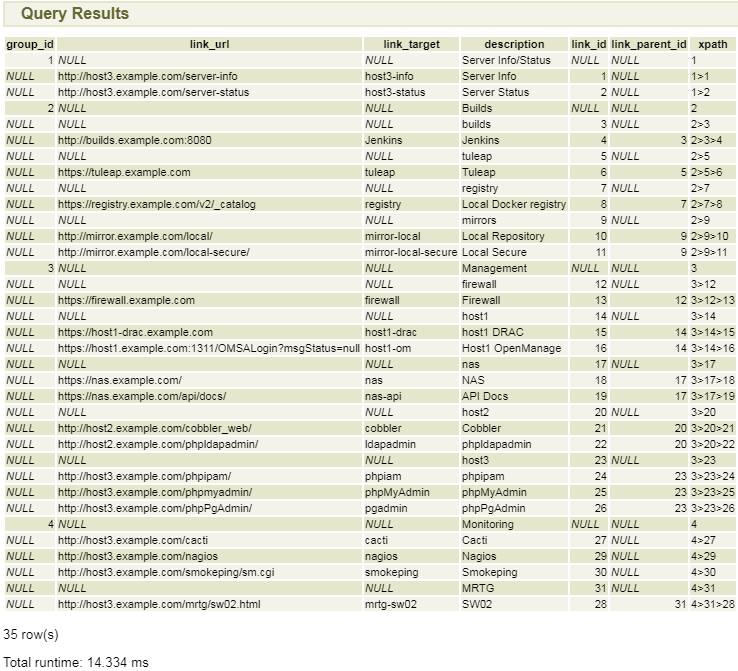
But with that said… here is the output.
It should be noted that:
A simple JOIN between the two tables and a sort on the group ID and description takes well over half that amount of time.
We are in fact doing three JOINs, not two.
Each query on item_links is taking about 4.5ms, meaning that even if we group things as we produce each query level, we would be talking roughly 18ms (3 levels, and an empty 4th level), and were we to not group them, but to do a simple one by one query, we would spend over 60ms just querying for children for rows which have none. And that would still require our taking the results and interleaving them with their parent records, while here, we need only look at the length of the xpath column, see we need to add another layer or close one, and continue from there… and we could even have computed a depth in the results, had we desired to do so.
For Further Reading
So, with this, here are a few handy links for you if you wish to learn more about them, as they are available in many of the current SQL server implementations out there today.
A few weeks ago, I posted an entry about why I use windows. Here is part of why I hate it, and why I do so less than willingly (to put it mildly).
For some months, I have been having a worsening problem with my browser and windows as a whole not being able to do DNS lookups. If you are one of those who is not aware of what this means, think of it this way… you want to drive someplace, but you don’t have the address or know how to get there. So, you try to make a phone call to a friend who knew where it was… only… that does not work. So while my browser knew the name of sites like “www.google.com”, “www.gmail.com” or “www.facebook.com”, it could not get this translated to values like “172.217.15.68” to allow me to do what I wanted.
Now, with a problem like this, people typically talk about changing your network settings to use a different DNS server to give you these sorts of answers, just like you might call a different person to give you the address. One reason you see this is because most folks do not run their own DNS server, and do not have the ability look at things in details on the DNS server end of things… but I do, in part because it serves up addresses only it has at hand. But, this also means that I have a much better view on things, to know where the problem is and is not… and rather than blame some DNS server, I know the problem is inside the machine which is running Windows… someplace. And here is how I know this…
As I sit here, as with any other day, besides the browser windows/tabs, I have connections open (using SSH) to terminal sessions on various Linux servers, along with a command.com session, and more. And add to this that for the past month or so, I have been capturing all network traffic associated with my DNS servers. And so, here is what I know/see.
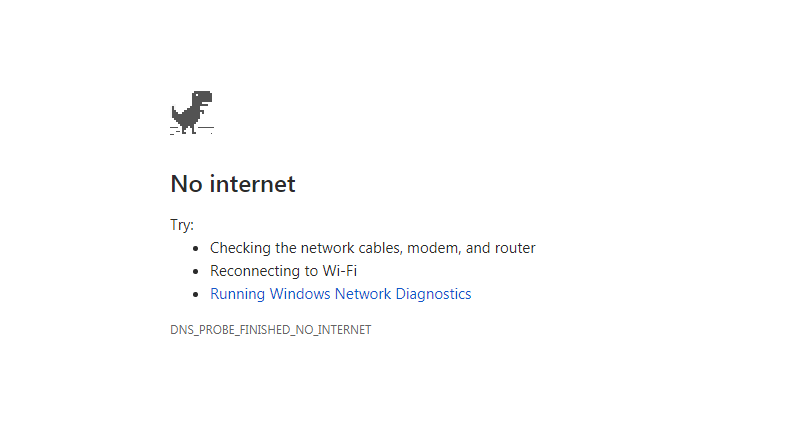
To start with, my browser or other applications report that they are unable to look up the remote host. If you use Chrome, you probably remember this as the screen with the T-Rex which you can also use to play a game jumping over cacti and the like like this…
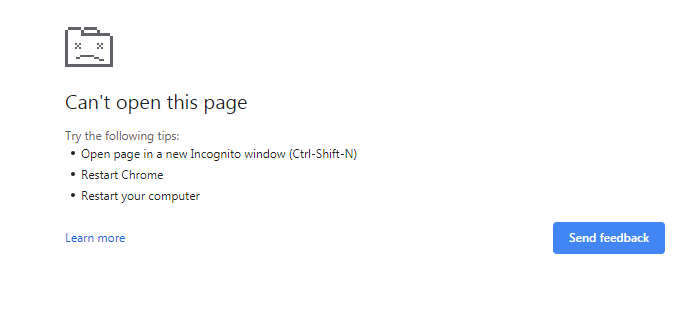
Or the just as frustrating and non-informative one like this…
I then pull up my command.com session, and do things like:
Ping 8.8.8.8 (one of Google’s DNS servers… that works fine).
Ping my own DNS server at 192.168.xxx.xxx, which also works fine.
Do a ping www.google.com or some similar host, which fails, telling me that the host name could not be found.
Do a nslookup www.google.com which also fails.
I then pull up one of my terminal sessions on a machine other than one hosting my DNS, and do a ping www.google.com just like I did before, and that works.
At this point, I know the problem is almost certainly inside Winblows, but I confirm this by doing the following:
In the command.com window, ipconfig /all shows the proper DNS servers.
I do a ipconfig /flushdns which reports it succeeded, but everything still fails.
Even doing a ipconfig /release and then a ipconfig /renew does not fix the issue.
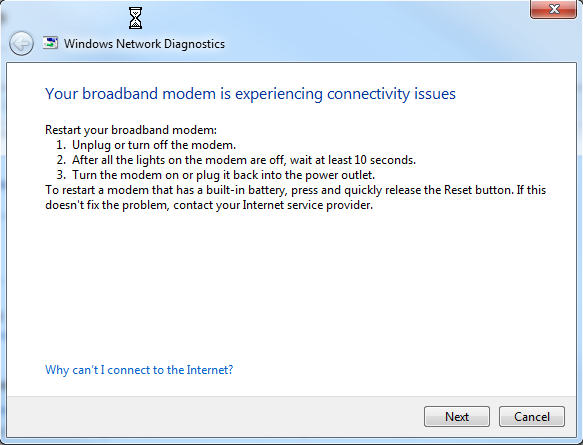
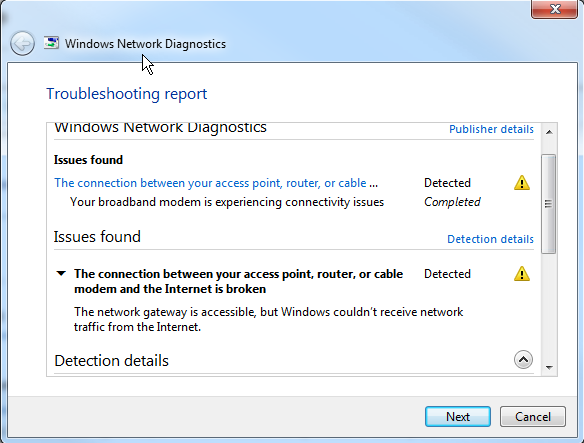
Generally, by this time, my antivirus (AVG) refuses to respond, and I cannot turn it off temporarily. And only the solution is to reboot. But the real kicker… having Winblows diagnose the problem gives me the following screens…
My response to this is…
The real kicker is when I open up my network traffic captures… when this is happening, there is absolutely no sign of any DNS requests from my Winblows box. NOT ONE FRELLING PACKET!!!
Now, if there were log files (nothing shows up in the Event Viewer), maybe I could figure out if for example, AVG ended up wedged or swapped out. Or perhaps it is the Winblows DNS client. But after months of looking, nada, zilch, nothing to indicate where I might find logs or enable debugging. And this leaves me wanting to do this with Winblows, AVG and the rest…
But for now, between the cost and other issues with AVG on top of this problem, I am starting by switching to a different anti-virus. I may or may not come back to AVG, which I started using some years ago because it supported both my Winblows machines and my Android cell phones… but at this point, I am severely disinclined to do so.
I have been using Chrome for many years now, having become a convert from Firefox when it first came out. But it has been getting to be a persistent pain on a number of fronts, and I have almost reached my Popeye moment, where “I have had all I can stands, and I can stands no more…”
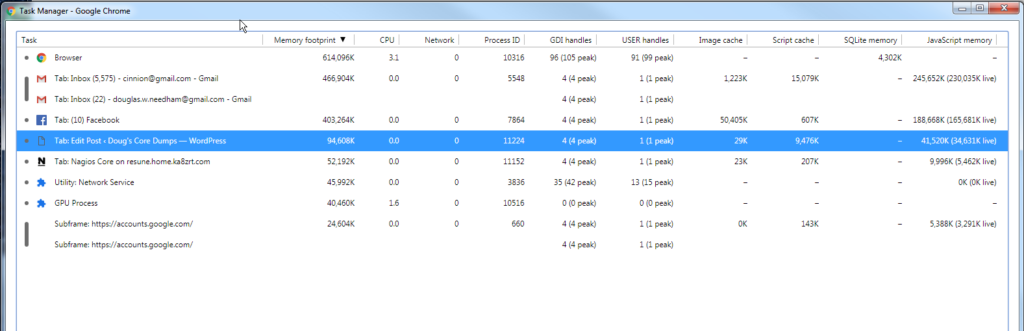
One of the first items which started becoming an issue was the memory use. Some time back, Chrome started getting really bad about is memory use, and it became even more visible when it started breaking out every… single… frelling… frame… on… every… single… tab. And this was true even if the tab had been in the background for hours, such as ones for Facebook, PHP.net, Python.org or whatever I happen to be working on that day. But routinely, Chrome is using over 2GB of RAM on my laptop with 4GB, even when I have just half a dozen tabs open (FB, 2 gmail, Nagios, Jenkins, and this one), having recently restarted, I have this in the task manager…
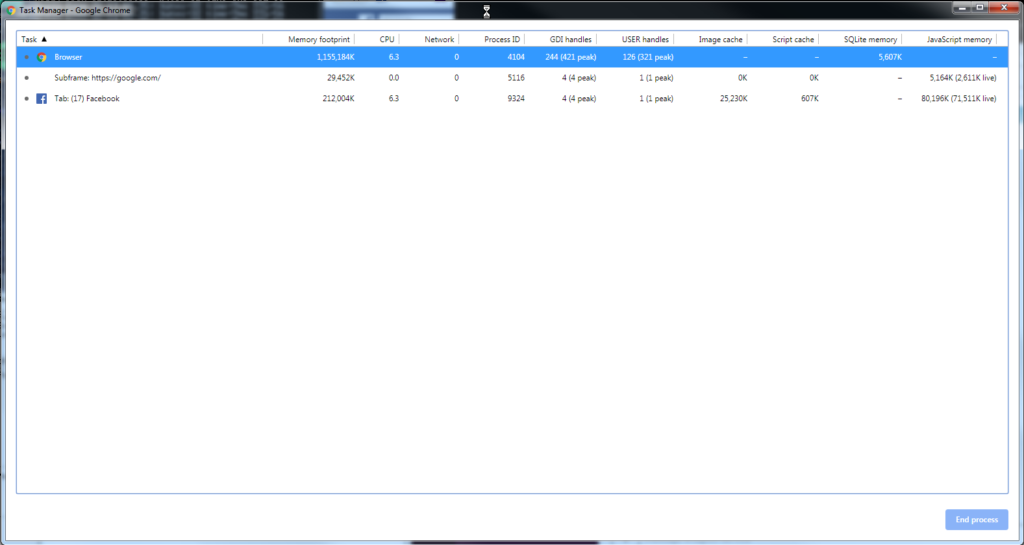
Notice how much the browser itself is using… 625MB… roughly the amount of an entire frelling CDROM. And I have not even done any real scrolling on any of these!!! But shortly before this, I had the following, from where I had last night been working with Jenkins builds, reading email, watching a few YouTube videos, and replying to some friends posts on FB… and then killed all the tabs before going to bed, rather than just restarting the browser.
Yes, your eyes are not deceiving you… over 1GB of RAM for just the browser itself.
Now, is it a memory leak, or what?? I think that given the 625MB which it started at, it is more just a design issue. And the reason I say this is that I have seen similar design issues, like MicroSoft wanting to load an entire 9GB database into memory when you wanted to back it up, or all the infamous “blue screen of death” crashes, or countless others by many other companies. And why is this?? In this case, it is because I have long been used to working with programs and having resource limits which both the application and the operating system itself put into place. If I want to open a 512MB log file, depending on various things, I can either be told “No, you need to break the file down into smaller parts”, or I get asked if I really want to open that large of a file. And at one point, browsers used to have controls on how much space they would use, both on disk and in memory, before they would just reload things from the network. But following in the infinitesimal wisdom of MicroSoft, Apple and others, things have gone beyond the point of hiding settings in a screen someplace, to in some cases, just making it something you cannot set, or have to use some poorly, if not undocumented command line option which requires changing something in the windows registry or in the shortcut properties (if you are on one of those platforms). But it forgets that basic idea of resource limits… if any site goes over a certain size in terms of memory usage, just like good operating systems and well designed applications do, Chrome should be saying “Are you really sure”, or be saying “This site wants to use too much memory, click here to adjust the limit for this site”. And, there needs to be a better way to collect information about all the browser tasks, and a better way to pass this information back to the development team. And more fundamentally, Chrome should support putting tabs to sleep when they have not been active for more than a short time, and especially getting all the frames under control. (But let us be honest… they will not, because Chrome comes from Google, which makes obscenely massive amounts of money from ads of all forms, and I think we all have seen the news articles such as this, and so to put them to sleep and potentially reduce their revenue…not likely.) But there is more to my growing dissatisfaction than just with the memory usage.
Another issue is that with the latest couple of updates, Chrome has not been filling in passwords which I have told it to save. It would be one thing if my passwords were a mix of things like “42 is the answer!”, “G0 Buckeyes!” and such, but they are not. My “simple” passwords might be like ‘<F7FZihp’ or ‘tqBfj0tf’ (if I have to type them… that last being an example of using letters from a memorable phrase such as “the quick brown fox jumped over the fence”, then playing with numbers and letters. But then, more often, I am using passwords like ‘?~<$7B62NO$n$+;;LU:,’, consisting of something between 16 and 24 characters (depending on the site, or perhaps more), generated and stored by a program, and also remembered and supplied by my browser… WHEN THE FRELLING BROWSER WORKS!!! And as you can guess, the past few updates of Chrome have not been working. And while one might ask “Well, did they change the login form?” or other things, I know it is this way across the board… even on sites which I have written. Even my test sites, residing behind a firewall and absolutely inaccessible, use passwords like these.
And another issue is speed. This one seems to be worse when the browser is sucking up memory, so I suspect partly that the Windows 7 box I use much of the time is in such a bruised and battered state, that it is like two boxers who have gone 15+ rounds, cannot see, can barely stand, much less do what they are expected to do… routinely, I see pages taking 20-30 seconds to load, with no clues if it is the browser, Windows and its network stack (which would also include the antivirus software), or what. I really should look into things like what the server side sees with a packet trace sometime, but most of the time, I am mainly doing something else, and bringing up some documentation, responding to a message somebody sent me on FB, pulling up an email, or something else… and I know it is not my network… my servers are all reachable and talking among themselves fine, my FTTP connection is fairly idle, etc. And so…
But given all this, I am seriously considering moving back to Firefox as my primary browser.