
So, as a part of my working to retire an ancient (20 year old) server which I have been using as a NFS server, among other things, I had one major task before me… fix things so that my NAS server could be used for the what I intended. But I was having some issues around 8 years ago when I first tried this, and I don’t remember all the issues, since work kept me from attacking this problem at the time. With my NAS software, TrueNAS Core (back then, it was still called FreeNAS) being essentially EOL in favor of a new version with a different name, I decided to attack the upgrade to TrueNAS SCALE this week. I say “this week”, because I wanted to be sure to backup all the data I had only on my NAS server, and nowhere else. And when you are backing up multiple terabytes of data, even with gigabit ethernet, that takes quite a while. And, had it failed, I was just going to skip using the fancy NAS software with its ZFS filesystem, and go for a regular Linux install to make a NFS server initially, then add other services as I went along.
My first task was to try to reproduce some of the issues I was having. One of the biggest issues was that while my ancient NFS server worked without issues, it turns out that when trying to use my NAS server, I was being prompted for password, since my SSH keys were not being used. This is a huge issue for me, because I am always connecting between all my hosts (over 20 of them), and it goes from being just a nuisance to a major PITA. Back then, I suspect that I had just written it off as a SELinux issue, since around that time, I was really going in on the idea of having it in enforcing mode, rather than permissive mode. So, while reproducing it, I did a bit of digging (with far better knowledge of SELinux, sssd and idmapd), and found that back when I first had this problem, my user and group IDs were not being mapped correctly. But today, I got the critical clues with debugging turned on. The two key lines were:
Oct 19 10:36:29 devhost kernel: NFS: v4 server nas.xyzzy.ka8zrt.com does not accept raw uid/gids. Reenabling the idmapper.
Oct 19 10:36:24 devhost nfsidmap[1840]: nss_name_to_gid: name 'cinnion@xyzzy.ka8zrt.com' does not map into domain 'ka8zrt.com'This combination gave me the critical clue… idmapd might need tweaked. Sure enough, changing the domain name in /etc/idmapd.conf fixed that issue, and I am preparing to push that change out to all my other hosts. More on that in a bit.
So, to do the upgrade, I just selected the dropdown on the TrueNAS Core to select the latest stable TrueNAS SCALE release as documented in the migration guide as the update train. I then told it to download and apply the update, and about 30 minutes later… voilà (I love autocorrect for helping me add that accented character!). And here, I noticed the first of the minor gotchas… when trying to get at my home directory, I was getting an “Unknown error 521“. It turns out that the host I was using to do my testing had stale NFS information. Easy enough, just reboot to clear that mount to start fresh, and sure enough, it worked. (Sorry. No, I did not try just restarting the automounter or such, it is just a development server I use.)
Now, a second glitch I have run into is with ansible. I use a redis cache for storing facts about all my hosts, and it was confused and trying to use the path to python which was on the FreeBSD install of TrueNAS Core, not the one for the debian based TrueNAS SCALE. Easy fix…
[root@resune ansible]# redis-cli
127.0.0.1:6379> del ansible_factsnasAnd after that, my gather-facts playbook (full playbook can be seen here) got a second error. While it detects the server as a libvirt host, libvirt is apparently not running. Another easy fix… I just change
- name: Get guest virtual machines
virt:
command: list_vms
register: list_vms
when:
- ansible_facts['virtualization_role'] == "host"
- inventory_hostname != 'planys'
- name: Save guest virtual hosts as cachable fact
set_fact:
cacheable: yes
guest_vms: "{{ list_vms.list_vms }}"
when:
- ansible_facts['virtualization_role'] == "host"
- inventory_hostname != 'planys'
to
- name: Get guest virtual machines
virt:
command: list_vms
register: list_vms
when:
- ansible_facts['virtualization_role'] == "host"
- inventory_hostname != 'planys'
- inventory_hostname != 'nas'
- name: Save guest virtual hosts as cachable fact
set_fact:
cacheable: yes
guest_vms: "{{ list_vms.list_vms }}"
when:
- ansible_facts['virtualization_role'] == "host"
- inventory_hostname != 'planys'
- inventory_hostname != 'nas'
Notice the additional lines at the end of each task? Easy enough, and if/when I decide to actually host a virtual host there, I just remove those lines. But I am not likely to do that, as this is not as beefy a server as the one on which I run my virtual machines, such as my web server, which is dedicated to that task and currently has 4x the RAM and faster CPUs. And it certainly is the case given that the ZFS cache is taking around 75% of the RAM in this machine!
Now, to cleanup tasks, such as to copy my home directories from the old machine. Sure to take some time…
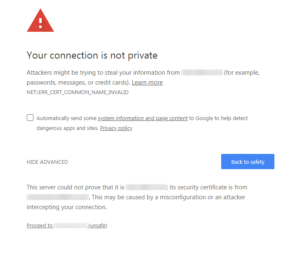 Notice… this has the “Proceed to…” link at the bottom, which the other screen I got when using the FQDN did not. But going this route, I was able to both re-enable the ability to use HTTP as well as HTTPS, turn off forced redirection by the app, and thanks to some digging, find out how to change these two settings from the CLI. And so, in case browsers across the board decide to do away with the “Proceed to” link in all cases, I am putting the info about changing the settings here for general consumption.
Notice… this has the “Proceed to…” link at the bottom, which the other screen I got when using the FQDN did not. But going this route, I was able to both re-enable the ability to use HTTP as well as HTTPS, turn off forced redirection by the app, and thanks to some digging, find out how to change these two settings from the CLI. And so, in case browsers across the board decide to do away with the “Proceed to” link in all cases, I am putting the info about changing the settings here for general consumption.