
A few weeks ago, I posted an entry about why I use windows. Here is part of why I hate it, and why I do so less than willingly (to put it mildly).
For some months, I have been having a worsening problem with my browser and windows as a whole not being able to do DNS lookups. If you are one of those who is not aware of what this means, think of it this way… you want to drive someplace, but you don’t have the address or know how to get there. So, you try to make a phone call to a friend who knew where it was… only… that does not work. So while my browser knew the name of sites like “www.google.com”, “www.gmail.com” or “www.facebook.com”, it could not get this translated to values like “172.217.15.68” to allow me to do what I wanted.
Now, with a problem like this, people typically talk about changing your network settings to use a different DNS server to give you these sorts of answers, just like you might call a different person to give you the address. One reason you see this is because most folks do not run their own DNS server, and do not have the ability look at things in details on the DNS server end of things… but I do, in part because it serves up addresses only it has at hand. But, this also means that I have a much better view on things, to know where the problem is and is not… and rather than blame some DNS server, I know the problem is inside the machine which is running Windows… someplace. And here is how I know this…
As I sit here, as with any other day, besides the browser windows/tabs, I have connections open (using SSH) to terminal sessions on various Linux servers, along with a command.com session, and more. And add to this that for the past month or so, I have been capturing all network traffic associated with my DNS servers. And so, here is what I know/see.
- To start with, my browser or other applications report that they are unable to look up the remote host. If you use Chrome, you probably remember this as the screen with the T-Rex which you can also use to play a game jumping over cacti and the like like this…
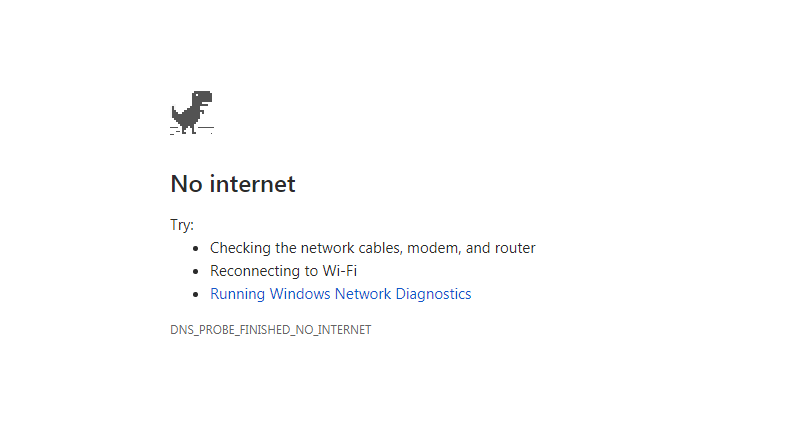
Or the just as frustrating and non-informative one like this…
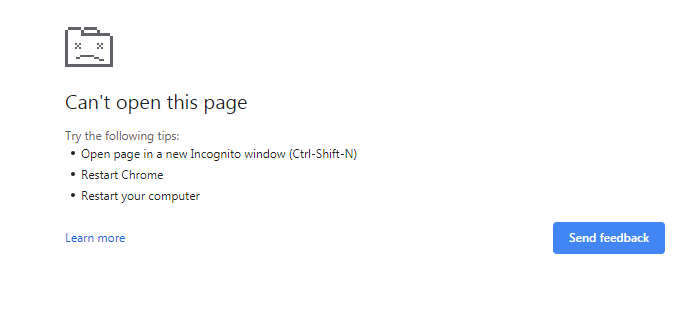
- I then pull up my command.com session, and do things like:
- Ping 8.8.8.8 (one of Google’s DNS servers… that works fine).
- Ping my own DNS server at 192.168.xxx.xxx, which also works fine.
- Do a
ping www.google.comor some similar host, which fails, telling me that the host name could not be found. - Do a
nslookup www.google.comwhich also fails.
- I then pull up one of my terminal sessions on a machine other than one hosting my DNS, and do a
ping www.google.comjust like I did before, and that works.
At this point, I know the problem is almost certainly inside Winblows, but I confirm this by doing the following:
- In the command.com window,
ipconfig /allshows the proper DNS servers. - I do a
ipconfig /flushdnswhich reports it succeeded, but everything still fails. - Even doing a
ipconfig /releaseand then aipconfig /renewdoes not fix the issue.
Generally, by this time, my antivirus (AVG) refuses to respond, and I cannot turn it off temporarily. And only the solution is to reboot. But the real kicker… having Winblows diagnose the problem gives me the following screens…
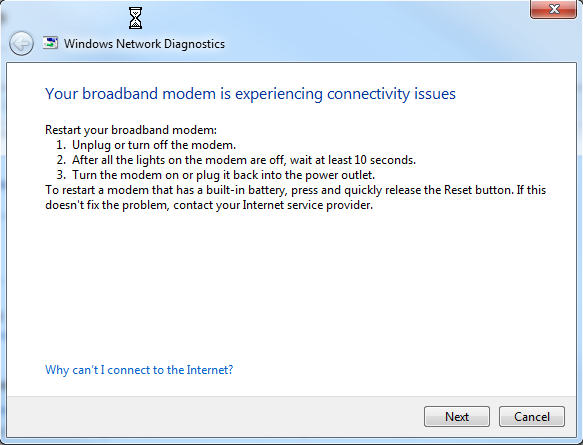
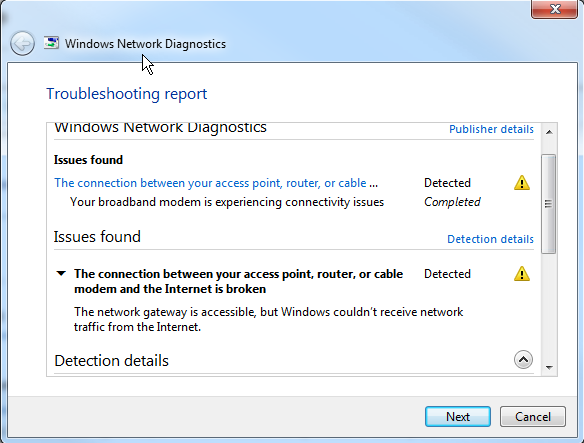
My response to this is…
The real kicker is when I open up my network traffic captures… when this is happening, there is absolutely no sign of any DNS requests from my Winblows box. NOT ONE FRELLING PACKET!!!
Now, if there were log files (nothing shows up in the Event Viewer), maybe I could figure out if for example, AVG ended up wedged or swapped out. Or perhaps it is the Winblows DNS client. But after months of looking, nada, zilch, nothing to indicate where I might find logs or enable debugging. And this leaves me wanting to do this with Winblows, AVG and the rest…
But for now, between the cost and other issues with AVG on top of this problem, I am starting by switching to a different anti-virus. I may or may not come back to AVG, which I started using some years ago because it supported both my Winblows machines and my Android cell phones… but at this point, I am severely disinclined to do so.
 So, after taking a bit of a break today, when I came back to this to try to debug the program which uses a halfway documented REST API, I could not use Chrome to access the WUI (Web UI), because the certificate had expired, and I use internal subdomains of my domain. Now mind you, I think that the HTTPS Everywhere initiative is the best thing since a meatloaf sandwich, and the work done by the ISRG, EFF, Google and others is great on the whole, but that is like saying someone did a great job at clearing a minefield to turn it into a school playground, when they missed at least one landmine. Worse… this application uses its own internal database to store its configuration, and all configuration is done through that same WUI Chrome is not allowing me to access to update the expired certificate.
So, after taking a bit of a break today, when I came back to this to try to debug the program which uses a halfway documented REST API, I could not use Chrome to access the WUI (Web UI), because the certificate had expired, and I use internal subdomains of my domain. Now mind you, I think that the HTTPS Everywhere initiative is the best thing since a meatloaf sandwich, and the work done by the ISRG, EFF, Google and others is great on the whole, but that is like saying someone did a great job at clearing a minefield to turn it into a school playground, when they missed at least one landmine. Worse… this application uses its own internal database to store its configuration, and all configuration is done through that same WUI Chrome is not allowing me to access to update the expired certificate.