
Common Table Expressions, or CTEs as they are often called, are an area of SQL which can by some be considered to be no different than magic. This is because few of us use them, and even fewer of us use them regularly enough to make them like the familiar of some powerful wizard in some book. And just like those familiars sometimes do in the books, they can give us great frustration or even turn upon us like some demon or Djinn who has escaped the bounds we thought would control them. But all the same, they can be quite useful, and indeed, necessary for us to have a performant application.
An introduction by example
And I myself have used them in a number of instances, including:
- Building up access control lists, where permissions can be inherited through roles.
- Generating menu hierarchies.
- Generating organizational charts.
- Analyzing data to generate reports.
In many of these cases, will see records in a database which point at other records of the same type. For example, here is one where we have an employee record, where there is a reference to the supervisor (their manager, boss, or whatever term is used at that level of the organization).
Now, when generating the org chart, moving downward from someone in the organization, such as an executive, we could do this in one of two ways, which basically boils down to:
- Have our program do the work.
- Have our database do the work.
In general, you are actually better off doing the latter, since:
- The database will tend to reside on a system with lots of resources (CPU, memory, disk), while your program may be running on a system with a much smaller set of resources, which can easily be replicated, etc.
- Each query sent to the database uses those resources, as well as network bandwidth, with there being costs being setup to validate and prepare each query, to run it, to prepare the results, as well as in the transmission and consumption of those results. And this does not even consider that a new database connection may need to be created.
- While we can certainly use things such as prepared statements in our program to reduce the overhead, and our queries may be simple, with a properly designed database, the database server can use its knowledge, as well as the expertise of its developers, to do things far better than we can.
Think about that employee database for a moment to see why. Suppose we are talking an employee database with 100,000 records (when I was at Lucent in what we termed the “Greater Bell Labs R&D”, we were over 150,000, so that is not an impossible figure), in which 90,000 of them are employees with nobody reporting to them, that could easily turn into 90,000 unnecessary queries sent to the server, or some similar nightmare, with all the associated execution time on both end, and all the requests going back and forth. So this is where a form of CTE called a recursive CTE helps us greatly.
Now, while referred to as a “recursive” CTE, it is really just a repeated iteration, where the records resulting from the prior pass are used to produce a new set of records, and it is repeated until no further records are returned to be placed into the temporary working table the server uses internally. Here is the CTE for the employees table.
WITH RECURSIVE report_tree ( employee_id, fname, lname, supervisor ) AS (
SELECT
employee_id,
fname,
lname,
supervisor
FROM employees
WHERE supervisor IS NULL
UNION ALL
SELECT
e.employee_id,
e.fname,
e.lname,
e.supervisor
FROM employees AS e
INNER JOIN report_tree AS emps ON (emps.employee_id = e.supervisor)
)
SELECT *
FROM report_tree;
When we look at this, we see the WITH block which defines the CTE as a prefix to the SELECT which uses it. That block consists of (in this case) an initial query (sometimes referred to as the “non-recursive” or “anchor” query), a UNION, and then the “recursive” portion, which references the containing CTE. In this case, we first get the batch of employees who have no supervisor, which may in fact be just a single record, or could be multiple records (such as the CEO, CTO, CFO, CLO, etc.). And in the next iteration, the bottom part will get those who report to the first set, with the following iteration getting those who report to the second set, and so on.
The one issue with the above CTE is that the output order, put bluntly, sucks like the vacuum of intergalactic space. There is no easy way of taking the output records and sorting them to even remotely resemble the organization. But there is a way in which we can address this, as we will see later.
My most recent encounter… (an in depth look)
Now, the most recent item where I came across a structure which could use a CTE is this… I have a page which is displayed on some of my machines when I connect to them via my browser. For example, if I connect to my main administrative server, or to the machine which handles all my virtual machines, I get the following page (sanitized):
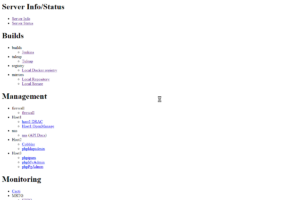
In looking to redesign this, and ultimately put it into a new application which I am writing (which I am currently calling Heimdallr), I wanted to put this into a database and turn it into a dynamic page. And when you look at this, it quickly becomes apparent that it should be represented as a hierarchy. It is, after all, yet another hierarchical menu, with all but the top nodes being HTML list items, and each leaf item having an associated URL, a target window (hidden to the viewer). Indeed, here it is in its source form:
<html>
<head>
<title>Monitoring</title>
</head>
<body>
<h1>Server Info/Status</h1>
<ul>
<li><a href="/server-info" target="server-info">Server Info</a></li>
<li><a href="/server-status" target="server-status">Server Status</a></li>
</ul>
<h1>Builds</h1>
<ul>
<li>builds
<ul>
<li><a href="http://builds.example.com:8080" target="Jenkins">Jenkins</a></li>
</ul>
</li>
<li>tuleap
<ul>
<li><a href="https://tuleap.example.com" target="tuleap">Tuleap</a></li>
</ul>
</li>
<li>registry
<ul>
<li><a href="https://registry.example.com/v2/_catalog" target="registry">Local Docker registry</a></li>
</ul>
</li>
<li>mirrors
<ul>
<li><a href="http://mirror.example.com/local/" target="mirror-local">Local Repository</a></li>
</ul>
<ul>
<li><a href="http://mirror.example.com/local-secure/" target="mirror-local-secure">Local Secure</a></li>
</ul>
</li>
</ul>
<h1>Management</h1>
<ul>
<li>firewall
<ul>
<li><a href="https://gateway.example.com" target="gateway" rel="noreferrer">Firewall</a></li>
</ul>
</li>
<li>Host1
<ul>
<li><a href="https://host1-drac.example.com" target="host1-drac">host1 DRAC</a></li>
<li><a href="https://host1.example.com:1311/OMSALogin?msgStatus=null" target="host1-om">Host1 OpenManage</a></li>
</ul>
</li>
<li>nas
<ul>
<li><a href="https://nas.example.com/" target="nas">nas</a> (<a href="https://nas.example.com/api/docs/" target="nas-api">API Docs</a>)</li>
</ul>
</li>
<li>Host2
<ul>
<li><a href="http://host2.example.com/cobbler_web/" target="cobbler">Cobbler</a></li>
<li><a href="http://host2.example.com/phpldapadmin/" target="ldapadmin">phpldapadmin</a></li>
</ul>
</li>
<li>Host3
<ul>
<li><a href="http://host3.example.com/phpipam/" target="phpiam">phpipam</a></li>
<li><a href="http://host3.example.com/phpmyadmin/" target="phpMyAdmin">phpMyAdmin</a></li>
<li><a href="http://host3.example.com/phpPgAdmin/" target="pgadmin">phpPgAdmin</a></li>
</ul>
</li>
</ul>
<h1>Monitoring</h1>
<ul>
<li><a href="/cacti" target="cacti">Cacti</a></li>
<li>MRTG
<ul>
<li><a href="/mrtg/sw02.html" target="mrtg-sw02">SW02</a></li>
</ul>
</li>
<li><a href="/nagios" target="nagios">Nagios</a></li>
<li><a href="/smokeping/sm.cgi" target="smokeping">Smokeping</a></li>
</ul>
</body>
</html>
So, the first pass of this becomes the following database tables, shown in graphical format:
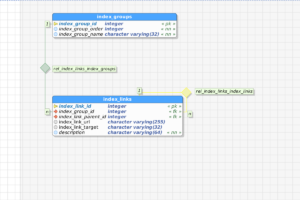
The index_groups table becomes something like this (intentionally shown as if “Management” was added after the fact):
| ID | Order | Text |
| 1 | 1 | Server Info/Status |
| 2 | 2 | Builds |
| 3 | 4 | Monitoring |
| 4 | 3 | Management |
While index_links contains records like the following:
| Link ID | Group ID | Parent Link ID | URL | Target | Description |
| 1 | 3 | firewall | |||
| 2 | 1 | https://gateway.example.com | gateway | Firewall | |
| 3 | 3 | Host1 | |||
| 4 | 3 | https://host1-drac… | drac | host1 DRAC | |
| 5 | 3 | https://host1:1311 | host1-om | Host1 OpenManage | |
| 6 | 3 | Host2 | |||
| 6 | 6 | https://host2… | host2-cobbler | Cobbler |
Now, as I said above, we could do this with loops making queries, but remember those 90,000 employees? While this menu only has 31 records half of them have no children, so we would be making roughly 16 queries with no results.
NOTE: Yes, we could group them and use queries containing code like WITH index_link_parent_id IN [ 1,2,3,4 ], but that quickly becomes complex, and could run into some limit. So again… why not let the SQL server do what it has been designed, and indeed is optimized to do.
So, how can we get those records out, and have them in an nice order, unlike the employee list? The first part is to have each record contain what is often referred to as an XPATH… a string which indicates how we arrived at the record in question. In this example, we are not going to use the /node1/node2/... syntax, but something similar… we will take the unique ID of each record in index_links, and add it onto a string, and each child will add theirs onto the end, using a ‘>’ character as a separator. It could be just about anything consistent, such as a colon, a dash, a period or a comma… just something which does not show up in our IDs, so we know where one ID ends and the next child’s begins. Were we to add an order to those records, we would just use it instead (or perhaps the order and ID, if we allowed for duplicate order values). And, as an added bonus, we will also use a trick to make the records of index_groups look like the records of index_links, so that we have rows for those records included in their spots in the hierarchy. And so, we have this CTE to get the data:
WITH RECURSIVE menutree (group_id, link_url, link_target, description, link_id, link_parent_id, xpath) AS (
SELECT -- Non-recursive
index_group_id,
CAST(NULL AS CHARACTER VARYING) AS link_url,
CAST(NULL AS CHARACTER VARYING) AS link_target,
CAST(index_group_name AS CHARACTER VARYING(64)),
CAST(NULL AS INTEGER) AS link_id,
CAST(NULL AS INTEGER) AS parent_id,
CONCAT('', index_group_order)
FROM index_groups
UNION
SELECT -- Recursive
CAST(NULL AS INTEGER),
l.index_link_url,
l.index_link_target,
CAST(l.description AS CHARACTER VARYING),
l.index_link_id,
l.index_link_parent_id,
CONCAT(mtree.xpath, '>', l.index_link_id)
FROM index_links l
INNER JOIN menutree mtree ON (
(l.index_link_parent_id IS NULL AND l.index_group_id = mtree.group_id)
OR
(l.index_link_parent_id IS NOT NULL AND l.index_link_parent_id = mtree.link_id)
)
)
SELECT * FROM menutree
ORDER BY xpath;
The non-recursive part starts by getting the records out of index_groups, and adding in columns with NULL values to make those look like the other records, and then in the “recursive” block, we have our query to add on the next set of records. The things to note here are:
- We are using column names on the CTE itself to save ourselves some typing.
- For our INNER JOIN… ON, we have two conditions or’ed together.
- A condition to join our group and link records for the first round of joining, and
- A condition to join child links to their parent links.
- We are having to use CAST() to have our column types match up, which is one reason why a CTE such as this can be particularly tricky.
- The order is not exactly identical. In particular, the fact that the MRTG record was added last and the SW02 record placed under it, as if by an afterthought, means that the MRTG entry and its children will come last, rather than following the entry for Cacti.
But with that said… here is the output.
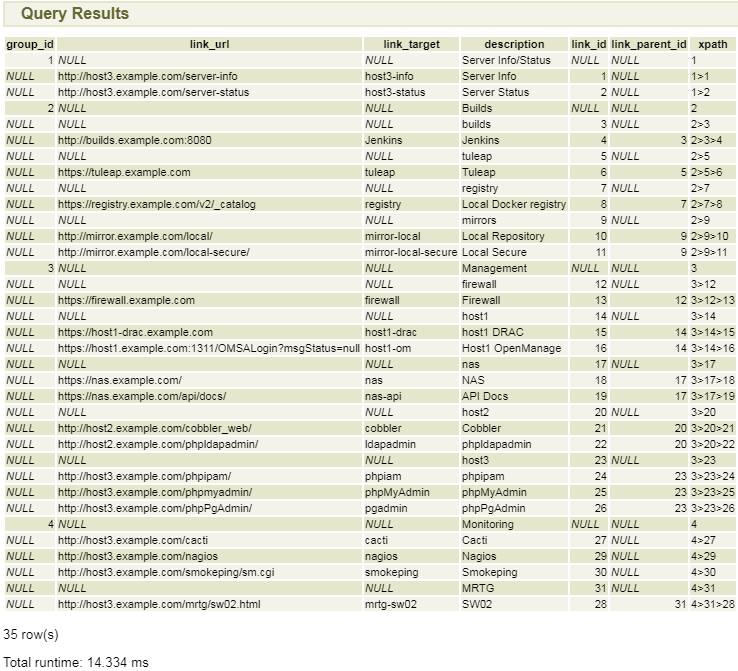
It should be noted that:
- A simple JOIN between the two tables and a sort on the group ID and description takes well over half that amount of time.
- We are in fact doing three JOINs, not two.
- Each query on
item_linksis taking about 4.5ms, meaning that even if we group things as we produce each query level, we would be talking roughly 18ms (3 levels, and an empty 4th level), and were we to not group them, but to do a simple one by one query, we would spend over 60ms just querying for children for rows which have none. And that would still require our taking the results and interleaving them with their parent records, while here, we need only look at the length of thexpathcolumn, see we need to add another layer or close one, and continue from there… and we could even have computed a depth in the results, had we desired to do so.
For Further Reading
So, with this, here are a few handy links for you if you wish to learn more about them, as they are available in many of the current SQL server implementations out there today.
- https://en.wikipedia.org/wiki/Hierarchical_and_recursive_queries_in_SQL
- https://www.postgresql.org/docs/10/queries-with.html
- https://www.essentialsql.com/introduction-common-table-expressions-ctes/
- https://www.essentialsql.com/recursive-ctes-explained/
- https://www.citusdata.com/blog/2018/05/15/fun-with-sql-recursive-ctes/
- https://docs.microsoft.com/en-us/sql/t-sql/queries/with-common-table-expression-transact-sql?view=sql-server-2017
 Notice… this has the “Proceed to…” link at the bottom, which the other screen I got when using the FQDN did not. But going this route, I was able to both re-enable the ability to use HTTP as well as HTTPS, turn off forced redirection by the app, and thanks to some digging, find out how to change these two settings from the CLI. And so, in case browsers across the board decide to do away with the “Proceed to” link in all cases, I am putting the info about changing the settings here for general consumption.
Notice… this has the “Proceed to…” link at the bottom, which the other screen I got when using the FQDN did not. But going this route, I was able to both re-enable the ability to use HTTP as well as HTTPS, turn off forced redirection by the app, and thanks to some digging, find out how to change these two settings from the CLI. And so, in case browsers across the board decide to do away with the “Proceed to” link in all cases, I am putting the info about changing the settings here for general consumption. So, after taking a bit of a break today, when I came back to this to try to debug the program which uses a halfway documented REST API, I could not use Chrome to access the WUI (Web UI), because the certificate had expired, and I use internal subdomains of my domain. Now mind you, I think that the HTTPS Everywhere initiative is the best thing since a meatloaf sandwich, and the work done by the ISRG, EFF, Google and others is great on the whole, but that is like saying someone did a great job at clearing a minefield to turn it into a school playground, when they missed at least one landmine. Worse… this application uses its own internal database to store its configuration, and all configuration is done through that same WUI Chrome is not allowing me to access to update the expired certificate.
So, after taking a bit of a break today, when I came back to this to try to debug the program which uses a halfway documented REST API, I could not use Chrome to access the WUI (Web UI), because the certificate had expired, and I use internal subdomains of my domain. Now mind you, I think that the HTTPS Everywhere initiative is the best thing since a meatloaf sandwich, and the work done by the ISRG, EFF, Google and others is great on the whole, but that is like saying someone did a great job at clearing a minefield to turn it into a school playground, when they missed at least one landmine. Worse… this application uses its own internal database to store its configuration, and all configuration is done through that same WUI Chrome is not allowing me to access to update the expired certificate.